PROCESSAMENTO
DIGITAL DE IMAGENS
Classificação
de Imagens
e obtenção de atributos
Rogério
Perino de Oliveira Neves
Aqui será sintetizado o quadro fundamental do processo de reconhecimento e classificação não-supervisionada de imagens, sendo utilizadas como fontes imagens do projeto VSLD* (Vegetable Specimen Leaf Database, ver apêndice), que dispõe de uma ampla coleção de imagens de alta definição, permitindo visualização clara dos resultados obtidos pelo processo automático e comparação com a classificação realizada visualmente.
As estrutura do processo de classificação pode ser sintetizada pela ordem:
- Aquisição da imagem
- Tratamento da imagem
- Identificação e separação de objetos (formas e figuras)
- Obtenção de atributos (features)
- Análise dos classificadores
- Classificação (clusterização)
- Teste
As fases serão tratadas em detalhes nos próximos tópicos, visando o entendimento do processo, estendendo sua aplicação a problemas generalizados em tratamento e classificação de imagens.
Aquisição da imagem
A aquisição de imagens pode ser realizada utilizando-se qualquer dos diversos dispositivos que extraem imagens do mundo real, como câmeras CCD e scanners ou obtidas de outros programas que geram sinais de imagem inteligíveis de algum interesse, por técnicas de Ray-tracing, mapeamento conforme, etc.
No projeto VSLD, imagens de folhas pertencentes a várias espécies vegetais foram digitalizadas com o uso de um scanner e posteriormente separado em arquivos nomeados conforme o tipo do espécime e número da amostra:
Exemplo: T03F012.BMP – Tipo 3 amostra 12.
No exemplo classificatório abordado aqui, utilizaremos nove espécies diferentes de vegetais, com 150 amostras de folhas extraídas dessas espécies, que chamaremos T1 a T9, com amostras F001 a F150. Das 150 amostras, utilizaremos metade para treinar o sistema e outra metade para testar a eficiência do processo.

Tipos de folhas pertencentes as 9 espéciesamostradas
Tratamento da imagem
Uma vez adquiridas, as imagens podem precisar de algum tratamento, visando corrigir pequenos defeitos de digitalização, permitindo ao sistema uma melhor identificação dos atributos relevantes para classificação.
Entre os defeitos indesejados, podemos citar alguns mais comuns:
- Distribuição de histograma desbalanceada
- Ruído de alta freqüência
- Ruído de baixa freqüência (linhas e sombras)
- Moiré
- Aliasing
- Aspecto ou tamanho irregulares
Tais defeitos na amostragem devem ser tratados sensivelmente ao caso, utilizando técnicas como:
- Equalização de histograma
- Balanceamento de histograma
- Filtragem
- Re-amostragem
- Re-dimensionamento ou adição de tela (canvas)
A classificação requer que alguns parâmetros, que venham a ser utilizados como atributos, sejam mantidos na aquisição para que a comparação apresente os resultados desejados. Formas de tamanhos diferentes quando imageadas, devem ser mantidas em escala, caso desejemos utilizar sua área, perímetro ou atributos derivados destes como base de comparação. O re-dimensionamento de apenas algumas imagens pode invalidar esta característica para uso classificatório.
No caso sugerido aqui, as imagens foram adquiridas utilizando-se especificações padrão, visando a máxima redução de tratamentos posteriores. Porém, a extração de atributos necessita freqüentemente algum tipo de tratamento. As características adotadas para as imagens adquiridas foram:
- Resolução: 150x150 dpi
- Tamanho das imagens variável
- Imagens coloridas em 16 bits com fundo branco
Ainda foi tomado o cuidado de utilizar-se o mesmo equipamento, evitando mudanças na coloração e qualidade gráfica devido ao uso de equipamentos de diferentes padrões.
Identificação
e separação de objetos (formas ou figuras)
Visando identificar os objetos da imagem, devemos primeiramente saber como diferenciar o objeto de interesse do restante da imagem, através de sua cor, textura ou forma, e posteriormente identificar o procedimento para fazer a separação do objeto de forma automática computacionalmente.
O método utilizado aqui foi o “Bayesiano”, visando a separação da imagem do fundo pela identificação dos grupos de pixels pertencentes à figura e ao fundo pela distribuição do histograma.
Primeiramente obtemos uma imagem em 256 níveis de cinza da imagem colorida com 16 bits de profundidade. De forma que o valor de cada pixel da nova imagem será dado por:
![]()
Em seguida, levantamos seu histograma, utilizando a função histograma para o caso discreto:
Identificando no histograma a distribuição dos grupos distintos de pixels pertencentes à figura e ao fundo.
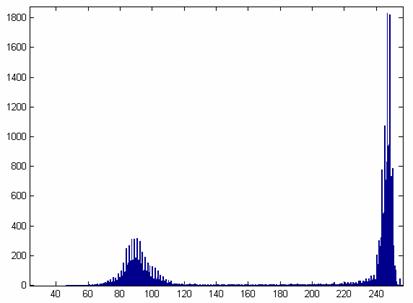
Identificação
de grupos distintos
caracterizando o objeto e o fundo branco
A separação do objeto do fundo se da então pelo separador bayesiano:
![]()
Onde K é o valor de decisão.
Para f(g|obj) a função histograma:
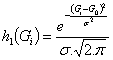
Para f(G|fundo) temos a
distribuição: 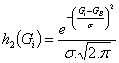
Temos que o
valor de K é dado por: ![]()
As
probabilidades encontradas foram: ![]() e
e ![]()
Efetuando
a operação para algumas imagens de vários tipos, chegamos a um valor médio de K=145, que utilizaremos para separação em batch ou batelada em todas as imagens.
No caso utilizado, identificamos facilmente o objeto na imagem devido ao fundo branco, que exclui qualquer dificuldade adicional, alem de pressupor que temos apenas um único objeto de estudo por imagem. Este caso ideal foi planejado já na aquisição, o que não se aplica à maioria das imagens comumente estudadas, sendo necessária a aplicação de algoritmos de busca ou detecção de bordas para separar corretamente diversas figuras contidas numa mesma imagem.
Obtenção de atributos
Uma vez corretamente identificados, os objetos ou figuras de estudo devem ser classificados conforme algum conjunto de regras determinadas. A escolha desse conjunto deve seguir padrões notóriamente relevantes para identificação do objeto, permitindo uma grande diversidade de aspectos em consideração, definindo clusters o mais espacialmente separados possivel num espaço multi-dimensional.
Algumas características que podem ser consideradas para este fim são:
 Altura
Altura- Largura
- Área
- Perímetro
- Simetria
- Deficiência convexa
- Razão dos eixos principais
- Entropia
- Energia elástica multi-escala
Atributos calculados:
- Circularidade: Perímetro2/Área
- Aspecto: razão Largura/Altura
- Razão Área/Perímetro
- Thines: 4
 Área/Perímetro2
Área/Perímetro2
Ainda podemos estrair features do esqueleto de Voronoi, obtido pela transformação de Voronoi:
- Numero de ramificações
- Ordens de ramificações
- Extensão do esqueleto
- Segmentação do dendograma
- Comprimento dos segmentos
- Transformada distância
Descritores de Fourier
Os descritores de Fourier são obtidos da transformada de Fourier da função descrita pela borda da figura devidamente discretizada, utilizando-se um método para mapear os pontos da borda em termos de coordenadas (X,Y) num vetor. Aplicando-se a transformada de Fourier à este vetor, obtemos um vetor com componentes:
f0, f1,
f2 f3...fn
Que são os descritores de fourier da silueta da figura. O termo f0 corresponde a média da forma, podendo ser descartada. Os n (com n arbitrário) próximos elementos podem ser utilizados como classificadores, uma vez que representam a imagem no espectro de freqüências.
A seguir, alguns algoritmos básicos para extração de features.
Área,
perímetro, altura, largura e derivados:
Para obtermos a área precisamos primeiramente da imagem binária da figura, de forma que varremos a imagem original, fazendo:
pixel=0 se fundo
pixel=1 se figura
Utilizamos como discriminador o próprio valor de K, obtemos a imagem binária fazendo pixel a pixel a operação lógica:
pixel_binaria=(pixel_imagem<K)
Obtemos um imagem com valores 0 e 1, onde 0 demarca fundo e 1 demarca figura.
Obtemos então a área somando o total de pixels iguais a 1.
O perímetro pode ser obtido identificando-se quantos pixels tem vizinhos 0, o perímetro será a soma do total desses pixels.
Para obter a altura e largura, temos que varrer a imagem guardando os valores máximos e mínimos de X e Y para os pixels acesos da figura.

Passos realizados: Escala de cinza, imagem binária e borda
Simetria bi-lateral
A simetria pode ser obtida seguindo-se os passos:
- Sabendo-se a altura e largura, localiza-se o centro da figura (objeto);
- Com base no centro da figura, obtemos a imagem espelho (mirror-fliped);
- Subtraímos a imagem espelhada da original, obtendo a diferença entre as duas metades vezes dois;
- Opcionalmente podemos dividir por dois, o que não alteraria uma comparação quantitativa do atributo entre diferentes imagens.

Calculo da simetria
Entropia
A formula da Entropia de Shanon é dada por:
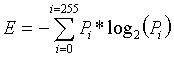
A entropia é uma medida da quantidade de informação contida na imagem, que aumenta na medida da rugosidade da superfície.
Os algoritmos utilizados devem ser adaptados conforme o caso, visando obter uma melhor classificação, a aplicação de cada método deve ser analisada e ponderada sensivel à aplicação desejada e ao conjunto de dados utilizados.
Análise dos classificadores
Definidos os atributos que serão utilizados para classificação, podemos ter uma idéia clara da eficiência da separação dos pontos aplicando os algoritmos em um conjunto imagens e observando sua distribuição no espaço do atributo.
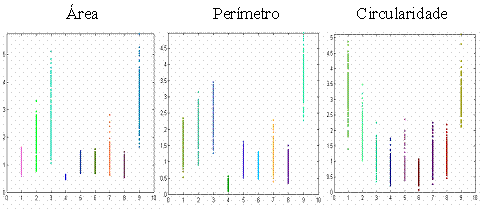
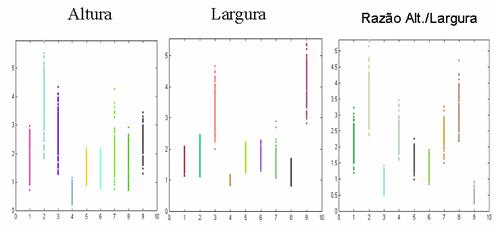
Algumas distribuições de pontos dos os atributoss extraídos
devidamente normalizados
Com base na separação realizada, devemos determinar uma combinação dos atributos obtidos e calculados de forma a obter a melhor distribuição possível num espaço de n dimensões, visando uma classificação mais clara e fácil, sem considerar ainda o método utilizado para classificação.

Representação
3-d do espaço de features, os tipos de folhas (em cores)
estão
separados utilizando-se os atributos Altura, Aspecto e Circularidade
Classificação
Os métodos de classificação podem ser supervisionados ou não supervisionados. Entre os métodos supervisionados mais comuns, podemos citar:
- Vizinho mais próximo
- K-vizinhos
- Bayes
E entre os não supervisionados:
- Aglomeração hierárquica
- K-médias
- K-medias Fuzzy
- Redes neurais
Abordaremos aqui apenas o uso de redes neurais, que se demonstrou o método mais eficiente para a maioria das aplicações, em concordância com a literatura. Os demais métodos podem ser obtidos em Gonzáles* (ver ref.).
Redes Neurais Artificiais
O uso de redes neurais é comumente aplicado ao reconhecimento de padrões dado o potencial de aprendizado de funções do sistema, que simula uma rede neural natural em muitos aspectos.
Na teoria de redes neurais artificiais, o neurônio pode ser representado por um corpo somático que apresenta um único axônio e uma árvore dendrital. Os estímulos recebidos na arvore dendrital são somados, passando por uma função de ativação que dispara um pulso no axônio sempre que o potencial ultrapassa um certo limite, conhecido como limiar de disparo.
O neurônio fundamental pode então ser representado da forma:
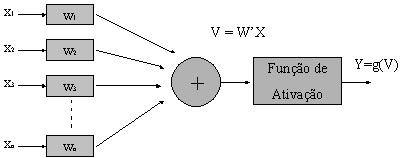
Representação do neurônio
Utilizamos como função de ativação a função sigmóide, com base radial.
A rede foi construída utilizando-se nove atributos de entrada, obtendo-se na saída a classificação, de forma que a saída que apresenta maior valor indica maior probabilidade de classificação.
Supondo que alguns clusters apresentam sobreposição, foram utilizadas duas camadas ocultas na tentativa de melhorar a distribuição dos clusters na base radial.
Foi utilizado o método de retropropagação de erro para treinamento da rede, utilizando-se como conjunto de treinamento a primeira metade das amostras de cada espécie. O critério de parada de treinamento estipulado foi: Uma vez que a rede apresente uma variação no erro de menos que 10-3, a rede é considerada treinada, uma vez que passou a apresentar baixo índice de aprendizado.
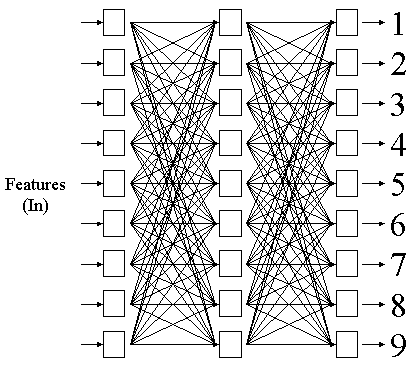
Rede utilizada para classificação
Teste dos resultados
Para testar a eficiência da classificação, utilizamos a “matriz de confusão”, aplicando os atributos referentes a segunda metade das amostras à entrada da rede, e observando a classificação na saída. Nas colunas temos os tipos que foram introduzidos na entrada da rede, nas linhas temos como cada tipo foi classificado pela rede neural.
Matriz de confusão
|
|
T1 |
T2 |
T3 |
T4 |
T5 |
T6 |
T7 |
T8 |
T9 |
|
T1 |
72 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
T2 |
0 |
69 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
T3 |
0 |
0 |
69 |
0 |
0 |
0 |
0 |
0 |
1 |
|
T4 |
0 |
0 |
0 |
75 |
0 |
0 |
1 |
0 |
0 |
|
T5 |
1 |
0 |
1 |
0 |
68 |
3 |
4 |
0 |
0 |
|
T6 |
1 |
0 |
1 |
0 |
7 |
71 |
0 |
0 |
0 |
|
T7 |
1 |
0 |
1 |
0 |
0 |
1 |
57 |
2 |
0 |
|
T8 |
0 |
6 |
0 |
0 |
0 |
0 |
13 |
73 |
0 |
|
T9 |
0 |
0 |
3 |
0 |
0 |
0 |
0 |
0 |
74 |
|
|
|
|
|
|
|
|
|
|
|
|
Total |
75 |
75 |
75 |
75 |
75 |
75 |
75 |
75 |
75 |
Podemos estipular uma medida quantitativa da eficiência da rede calculando o determinante da matriz de confusão, obtendo uma base para comparação entre diversos métodos e conjuntos de atributos de entrada. Quanto maior o determinante, maior o número de elementos na diagonal principal, e conseqüentemente maior a eficiência do método utilizado, considerando um mesmo conjunto de teste.
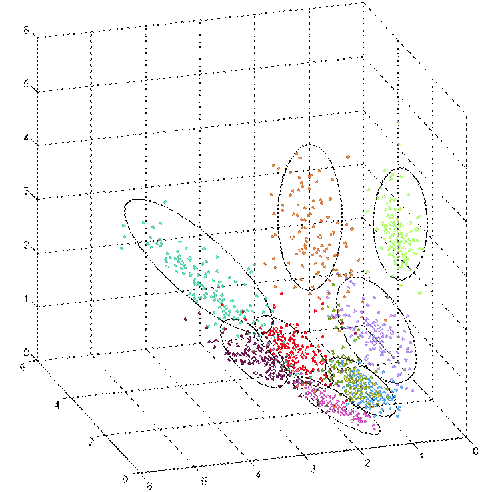
Exemplo
de clusterização em um espaço tri-dimensional
utilizando
redes neurais de base radial.
Apêndice
O projeto VSLD foi iniciado primeiramente como projeto de graduação da turma de formandos de 2000 no Instituto de Física de São Carlos, visando a classificação imediata de espécies vegetais em campo, com o uso de uma câmera CCD e um micro-computador portátil.
Alunos primariamente envolvidos no projeto são:
- Rogério Perino de Oliveira Neves
- Emerson Pedrino
- Leonardo Rugiero Bachega
Sob orientação do professor Luciano Fontoura da Costa.
O projeto visa posterior integração com estudantes de outras universidades, com o objetivo de expandir as capacidades do banco de dados.
Informações podem ser obtidas no site:
http://www.if.sc.usp.br/~rponeves/grad/metodos
Bibliografia
Rafael Gonzales Processamento digital de imagens
Arthur R. Weeks. Fundamentals of Eletronic Image Processing (1996). IEEE Press
Luciano Fontoura
Costa Digital Image
Processing (not published yet)
Kovács Fundamentos de Neurocomputação (1996).
Edição Acadêmica
Mathworks Inc. Matlab users Manual